Network
Network
Net
目前互联化的核心是建立在 TCP/IP 协议的基础上的, 这些协议将数据分割成小的数据包进行传输, 并且解决传输过程中各种各样复杂的问题. 关于协议的具体细节推荐阅读 W.Richard Stevens 的《TCP/IP 详解 卷1:协议》, 本文不做赘述, 只是列举一些常见的知识点, 新人推荐看《图解TCP/IP》, 抓包工具推荐看《Wireshark网络分析就这么简单》.
粘包
默认情况下, TCP 连接会启用延迟传送算法 (Nagle 算法), 在数据发送之前缓存他们. 如果短时间有多个数据发送, 会缓冲到一起作一次发送 (缓冲大小见 socket.bufferSize), 这样可以减少 IO 消耗提高性能.
如果是传输文件的话, 那么根本不用处理粘包的问题, 来一个包拼一个包就好了. 但是如果是多条消息, 或者是别的用途的数据那么就需要处理粘包.
可以参见网上流传比较广的一个例子, 连续调用两次 send 分别发送两段数据 data1 和 data2, 在接收端有以下几种常见的情况:
- A. 先接收到 data1, 然后接收到 data2 .
- B. 先接收到 data1 的部分数据, 然后接收到 data1 余下的部分以及 data2 的全部.
- C. 先接收到了 data1 的全部数据和 data2 的部分数据, 然后接收到了 data2 的余下的数据.
- D. 一次性接收到了 data1 和 data2 的全部数据.
其中的 BCD 就是我们常见的粘包的情况. 而对于处理粘包的问题, 常见的解决方案有:
-
- 多次发送之前间隔一个等待时间
-
- 关闭 Nagle 算法
-
- 进行封包/拆包
方案1
只需要等上一段时间再进行下一次 send 就好, 适用于交互频率特别低的场景. 缺点也很明显, 对于比较频繁的场景而言传输效率实在太低. 不过几乎不用做什么处理.
方案2
关闭 Nagle 算法, 在 Node.js 中你可以通过 socket.setNoDelay() 方法来关闭 Nagle 算法, 让每一次 send 都不缓冲直接发送.
该方法比较适用于每次发送的数据都比较大 (但不是文件那么大), 并且频率不是特别高的场景. 如果是每次发送的数据量比较小, 并且频率特别高的, 关闭 Nagle 纯属自废武功.
另外, 该方法不适用于网络较差的情况, 因为 Nagle 算法是在服务端进行的包合并情况, 但是如果短时间内客户端的网络情况不好, 或者应用层由于某些原因不能及时将 TCP 的数据 recv, 就会造成多个包在客户端缓冲从而粘包的情况. (如果是在稳定的机房内部通信那么这个概率是比较小可以选择忽略的)
方案3
封包/拆包是目前业内常见的解决方案了. 即给每个数据包在发送之前, 于其前/后放一些有特征的数据, 然后收到数据的时候根据特征数据分割出来各个数据包.
可靠传输
为每一个发送的数据包分配一个序列号(SYN, Synchronize packet), 每一个包在对方收到后要返回一个对应的应答数据包(ACK, Acknowledgement),. 发送方如果发现某个包没有被对方 ACK, 则会选择重发. 接收方通过 SYN 序号来保证数据的不会乱序(reordering), 发送方通过 ACK 来保证数据不缺漏, 以此参考决定是否重传. 关于具体的序号计算, 丢包时的重传机制等可以参见阅读陈皓的 《TCP的那些事儿(上)》 此处不做赘述.
window
TCP 头里有一个 Window 字段, 是接收端告诉发送端自己还有多少缓冲区可以接收数据的. 发送端就可以根据接收端的处理能力来发送数据, 从而避免接收端处理不过来. 详细参见陈皓的 《TCP的那些事儿(下)》
window 是否设置的越大越好?
类似木桶理论, 一个木桶能装多少水, 是由最短的那块木板决定的. 一个 TCP 连接的 window 是由该连接中间一连串设备中 window 最小的那一个设备决定的.
backlog
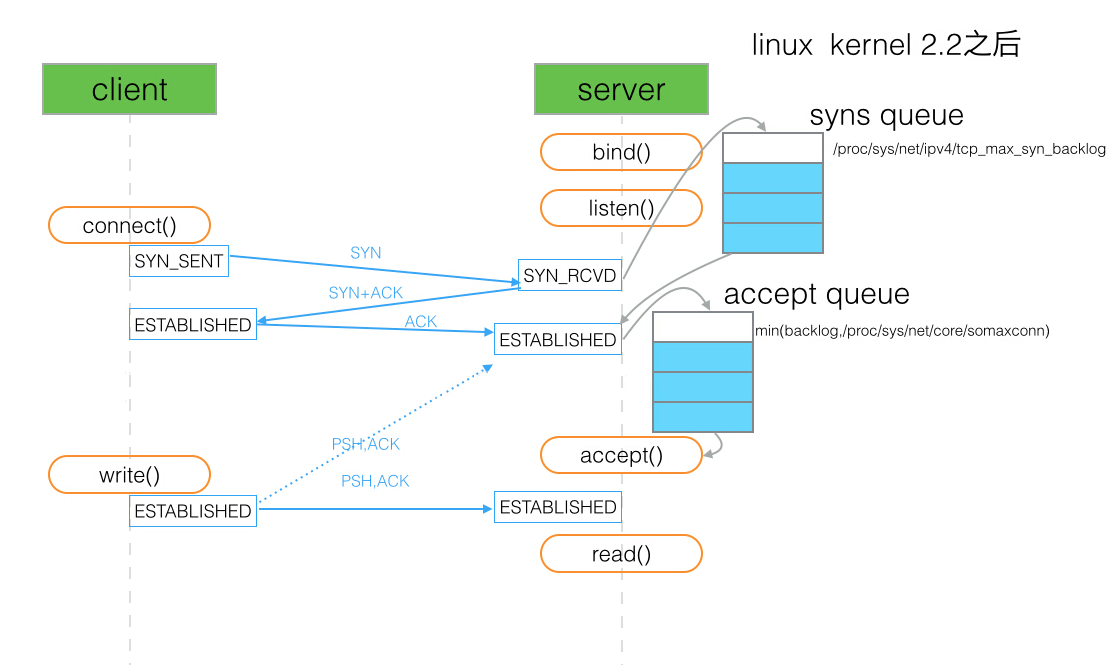
关于该 backlog 的定义参见 man 手册:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests.
backlog 用于设置客户端与服务端 ESTABLISHED 之后等待 accept 的队列长图 (如上图中的 accept queue). 如果 backlog 过小, 在并发连接大的情况下容易导致 accept queue 装满之后断开连接. 但是如果将这个队列设置的特别大, 那么假定连接数并发量是 65525, 以 php-fpm 的 qps 5000 为例, 处理完约耗时 13s, 而这段时间中连接可能早已被 nginx 或者客户端断开, 那么我们去 accept 这个 socket 时只会拿到一个 broken pipe (该例子出处见 PHP 源码 Set FPM_BACKLOG_DEFAULT to 511). 经过我也不懂的计算 backlog 的长度默认是 511.
另外提一句, 这个 backlog 是通过系统指定时是通过 somaxconn 参数来指定 accept queue 的. 而 tcp_max_syn_backlog 参数指定的是 SYN queue 的长度.
状态机
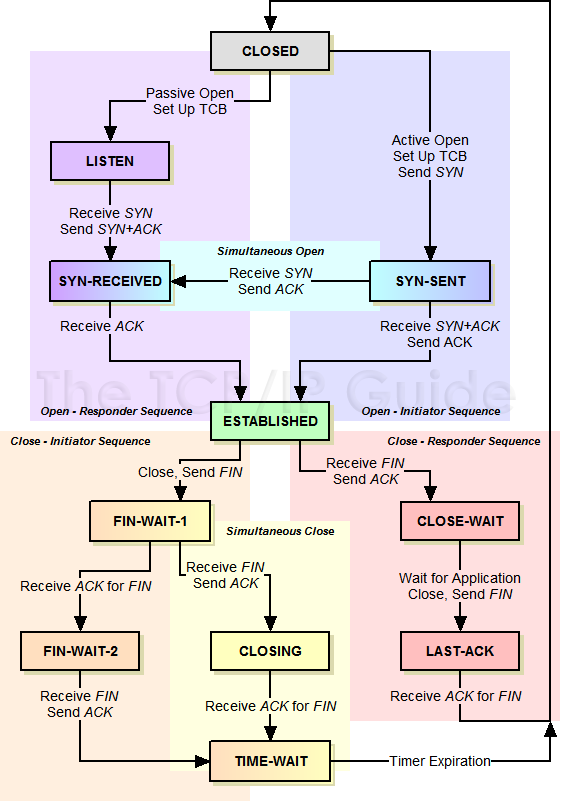
关于网络连接的建立以及断开, 存在着一个复杂的状态转换机制, 完整的状态表参见 《The TCP/IP Guide》
| state | 简述 |
|---|---|
| CLOSED | 连接关闭, 所有连接的初始状态 |
| LISTEN | 监听状态, 等待客户端发送 SYN |
| SYN-SENT | 客户端发送了 SYN, 等待服务端回复 |
| SYN-RECEIVED | 双方都收到了 SYN, 等待 ACK |
| ESTABLISHED | SYN-RECEIVED 收到 ACK 之后, 状态切换为连接已建立. |
| CLOSE-WAIT | 被动方收到了关闭请求(FIN)后, 发送 ACK, 如果有数据要发送, 则发送数据, 无数据发送则回复 FIN. 状态切换到 LAST-ACK |
| LAST-ACK | 等待对方 ACK 当前设备的 CLOSE-WAIT 时发送的 FIN, 等到则切换 CLOSED |
| FIN-WAIT-1 | 主动方发送 FIN, 等待 ACK |
| FIN-WAIT-2 | 主动方收到被动方的 ACK, 等待 FIN |
| CLOSING | 主动方收到了FIN, 却没收到 FIN-WAIT-1 时发的 ACK, 此时等待那个 ACK |
| TIME-WAIT | 主动方收到 FIN, 返回收到对方 FIN 的 ACK, 等待对方是否真的收到了 ACK, 如果过一会又来一个 FIN, 表示对方没收到, 这时要再 ACK 一次 |
TIME_WAIT 是连接的某一方 (可能是服务端也可能是客户端) 主动断开连接时, 四次挥手等待被断开的一方是否收到最后一次挥手 (ACK) 的状态. 如果在等待时间中, 再次收到第三次挥手 (FIN) 表示对方没收到最后一次挥手, 这时要再 ACK 一次. 这个等待的作用是避免出现连接混用的情况 (prevent potential overlap with new connections see TCP Connection Termination for more).
出现大量的 TIME_WAIT 比较常见的情况是, 并发量大, 服务器在短时间断开了大量连接. 对应 HTTP server 的情况可能是没开启 keepAlive. 如果有开 keepAlive, 一般是等待客户端自己主动断开, 那么TIME_WAIT 就只存在客户端, 而服务端则是 CLOSE_WAIT 的状态, 如果服务端出现大量 CLOSE_WAIT, 意味着当前服务端建立的连接大面积的被断开, 可能是目标服务集群重启之类.
UDP
| 协议 | 连接性 | 双工性 | 可靠性 | 有序性 | 有界性 | 拥塞控制 | 传输速度 | 量级 | 头部大小 |
|---|---|---|---|---|---|---|---|---|---|
| TCP | 面向连接 (Connection oriented) |
全双工(1:1) | 可靠 (重传机制) |
有序 (通过SYN排序) |
无, 有粘包情况 | 有 | 慢 | 低 | 20~60字节 |
| UDP | 无连接 (Connection less) |
n:m | 不可靠 (丢包后数据丢失) |
无序 | 有消息边界, 无粘包 | 无 | 快 | 高 | 8字节 |
UDP socket 支持 n 对 m 的连接状态, 在官方文档中有写到在 dgram.createSocket(options[, callback]) 中的 option 可以指定 reuseAddr 即 SO_REUSEADDR标志. 通过 SO_REUSEADDR 可以简单的实现 n 对 m 的多播特性 (不过仅在支持多播的系统上才有).
常见的应用场景
| 传输层协议 | 应用 | 应用层协议 |
|---|---|---|
| TCP | 电子邮件 | SMTP |
| 终端连接 | TELNET | |
| 终端连接 | SSH | |
| 万维网 | HTTP | |
| 文件传输 | FTP | |
| UDP | 域名解析 | DNS |
| 简单文件传输 | TFTP | |
| 网络时间校对 | NTP | |
| 网络文件系统 | NFS | |
| 路由选择 | RIP | |
| IP电话 | - | |
| 流式多媒体通信 | - |
简单的说, UDP 速度快, 开销低, 不用封包/拆包允许丢一部分数据, 监控统计/日志数据上报/流媒体通信等场景都可以用 UDP. 目前 Node.js 的项目中使用 UDP 比较流行的是 StatsD 监控服务.
HTTP
目前世界上运行最良好的分布式集群, 莫过于当前的万维网 (http servers) 了. 目前前端工程师也都是靠 HTTP 协议吃饭的, 所以 2-3 年的前端同学都应该对 HTTP 有比较深的理解了, 所以这里不做太多的赘述. 推荐书籍《图解HTTP》, 博客HTTP 协议入门.
另外最近几年开始大家对 HTTP 的面试的考察也渐渐偏向理解 RESTful 架构. 简单的说, RESTful 是把每个 URI 当做资源 (Resources), 通过 method 作为动词来对资源做不同的动作, 然后服务器返回 status 来得知资源状态的变化 (State Transfer);
method/status
因为 HTTP 的方法 (method) 与状态码 (status) 讲解太常见, 你可以使用如下代码打印出来自己看 Node.js 官方定义的, 完整的就不列举了.
const http = require('http');
console.log(http.METHODS);
console.log(http.STATUS_CODES);
一个常见的 method 列表, 关于这些 method 在 RESTful 中的一些应用的详细可以参见Using HTTP Methods for RESTful Services
| methods | CRUD | 幂等 | 缓存 |
|---|---|---|---|
| GET | Read | ✓ | ✓ |
| POST | Create | ||
| PUT | Update/Replace | ✓ | |
| PATCH | Update/Modify | ||
| DELETE | Delete | ✓ |
GET 和 POST 有什么区别?
网上有很多讲这个的, 比如从书签, url 等前端的角度去看他们的区别这里不赘述. 而从后端的角度看, 前两年出来一个 《GET 和 POST 没有区别》(出处不好考究, 就没贴了) 的文章比较有名, 早在我刚学 PHP 的时候也有过这种疑惑, 刚学 Node 的时候发现不能像 PHP 那样同时处理 GET 和 POST 的时候还很不适应. 后来接触 RESTful 才意识到, 这两个东西最根本的差别是语义, 引申了看, 协议 (protocol) 这种东西就是人与人之间协商的约定, 什么行为是什么作用都是"约定"好的, 而不是强制使用的, 非要把 GET 当 POST 这样不遵守约定的做法我们也爱莫能助.
跑题了, 简而言之, 讨论这二者的区别最好从 RESTful 提倡的语义角度来讲比较符合当代程序员的逼格比较合理.
POST 是新建 (create) 资源, 非幂等, 同一个请求如果重复 POST 会新建多个资源. PUT 是 Update/Replace, 幂等, 同一个 PUT 请求重复操作会得到同样的结果.
headers
HTTP headers 是在进行 HTTP 请求的交互过程中互相支会对方一些信息的主要字段. 比如请求 (Request) 的时候告诉服务端自己能接受的各项参数, 以及之前就存在本地的一些数据等. 详细各位可以参见 wikipedia:
主要区别在于, session 存在服务端, cookie 存在客户端. session 比 cookie 更安全. 而且 cookie 不一定一直能用 (可能被浏览器关掉). 服务端可以通过设置 cookie 的值为空并设置一个及时的 expires 来清除存在客户端上的 cookie.
出于安全考虑, 默认情况下使用 XMLHttpRequest 和 Fetch 发起 HTTP 请求必须遵守同源策略, 即只能向相同 host 请求 (host = hostname : port) 注[1]. 向不同 host 的请求被称作跨域请求 (cross-origin HTTP request). 可以通过设置 CORS headers 即 Access-Control-Allow- 系列来允许跨域. 例如:
location ~* ^/(?:v1|_) {
if ($request_method = OPTIONS) { return 200 ''; }
header_filter_by_lua '
ngx.header["Access-Control-Allow-Origin"] = ngx.var.http_origin; # 这样相当于允许所有来源了
ngx.header["Access-Control-Allow-Methods"] = "GET, POST, PUT, DELETE, PATCH, OPTIONS";
ngx.header["Access-Control-Allow-Credentials"] = "true";
ngx.header["Access-Control-Allow-Headers"] = "Content-Type";
';
proxy_pass http://localhost:3001;
}
注[1]:同源除了相同 host 也包括相同协议. 所以即使 host 相同, 从 HTTP 到 HTTPS 也属于跨域, 见讨论.
Script error.是什么错误? 如何拿到更详细的信息?
接上题, 由于同源性策略 (CORS), 如果你引用的 js 脚本所在的域与当前域不同, 那么浏览器会把 onError 中的 msg 替换为 Script error. 要拿到详细错误的方法, 处理配好 Access-Control-Allow-Origin 还有在引用脚本的时候指定 crossorigin 例如:
<script src="http://another-domain.com/app.js" crossorigin="anonymous"></script>
Agent
Node.js 中的 http.Agent 用于池化 HTTP 客户端请求的 socket (pooling sockets used in HTTP client requests). 也就是复用 HTTP 请求时候的 socket. 如果你没有指定 Agent 的话, 默认用的是 http.globalAgent.
另外, 目前在 Node.js 的 6.8.1(包括)到 6.10(不包括)版本中发现一个问题:
-
- 你将 keepAlive 设置为
true时, socket 有复用
- 你将 keepAlive 设置为
-
- 即使 keepAlive 没有设置成
true但是长时间内有大量请求时, 同样有复用 socket (复用情况参见@zcs19871221的解析)
- 即使 keepAlive 没有设置成
1 和 2 这两种情况下, 一旦设置了 request timeout, 由于 socket 一直未销毁, 如果你在请求完成以后没有注意清除该事件, 会导致事件重复监听, 且该事件闭包引用了 req, 会导致内存泄漏.
如果有疑虑的话可以参见 Node 官方讨论的 issue 以及引入此 bug 的 commit, 如果此处描述有疑问可以在本 repo 的 issue 中指出.
socket hang up
hang up 有挂断的意思, socket hang up 也可以理解为 socket 被挂断. 在 Node.js 中当你要 response 一个请求的时候, 发现该这个 socket 已经被 "挂断", 就会就会报 socket hang up 错误.
function socketCloseListener() {
var socket = this;
var req = socket._httpMessage;
// Pull through final chunk, if anything is buffered.
// the ondata function will handle it properly, and this
// is a no-op if no final chunk remains.
socket.read();
// NOTE: It's important to get parser here, because it could be freed by
// the `socketOnData`.
var parser = socket.parser;
req.emit('close');
if (req.res && req.res.readable) {
// Socket closed before we emitted 'end' below.
req.res.emit('aborted');
var res = req.res;
res.on('end', function() {
res.emit('close');
});
res.push(null);
} else if (!req.res && !req.socket._hadError) {
// This socket error fired before we started to
// receive a response. The error needs to
// fire on the request.
req.emit('error', createHangUpError()); // <------------------- socket hang up
req.socket._hadError = true;
}
// Too bad. That output wasn't getting written.
// This is pretty terrible that it doesn't raise an error.
// Fixed better in v0.10
if (req.output)
req.output.length = 0;
if (req.outputEncodings)
req.outputEncodings.length = 0;
if (parser) {
parser.finish();
freeParser(parser, req, socket);
}
}
典型的情况是用户使用浏览器, 请求的时间有点长, 然后用户简单的按了一下 F5 刷新页面. 这个操作会让浏览器取消之前的请求, 然后导致服务端 throw 了一个 socket hang up.
详见万能的 stackoverflow: NodeJS - What does “socket hang up” actually mean?
DNS
早期可以用 TCP/IP 通信之后, 有一个比较蛋疼的问题, 就是 ip 都是一串比较长的数字, 比较难记, 于是大家想了个办法, 给每个 ip 取个好记一点的名字比如 Alan -> 192.168.0.11 这样只需要记住好记的名字即可, 随着这个名字的规范化最终变成了今天的域名 (Domain name), 而帮助别人记录这个名字的服务就叫域名解析服务 (Domain Name Service).
DNS 服务主要基于 UDP, 这里简单介绍 Node.js 实现的接口中的两个方法:
| 方法 | 功能 | 同步 | 网络请求 | 速度 |
|---|---|---|---|---|
| .lookup(hostname[, options], cb) | 通过系统自带的 DNS 缓存 (如 /etc/hosts) |
同步 | 无 | 快 |
| .resolve(hostname[, rrtype], cb) | 通过系统配置的 DNS 服务器指定的记录 (rrtype指定) | 异步 | 有 | 慢 |
DNS 模块中 .lookup 与 .resolve 的区别?
当你要解析一个域名的 ip 时, 通过 .lookup 查询直接调用 getaddrinfo 来拿取地址, 速度很快, 但是如果本地的 hosts 文件被修改了, .lookup 就会拿 hosts 文件中的地方, 而 .resolve 依旧是外部正常的地址.
由于 .lookup 是同步的, 所以如果由于什么不可控的原因导致 getaddrinfo 缓慢或者阻塞是会影响整个 Node 进程的, 参见文档.
hosts 文件是什么? 什么叫 DNS 本地解析?
hosts 文件是个没有扩展名的系统文件, 其作用就是将网址域名与其对应的 IP 地址建立一个关联“数据库”, 当用户在浏览器中输入一个需要登录的网址时, 系统会首先自动从 hosts 文件中寻找对应的IP地址.
当我们访问一个域名时, 实际上需要的是访问对应的 IP 地址. 这时候, 获取 IP 地址的方式, 先是读取浏览器缓存, 如果未命中 => 接着读取本地 hosts 文件, 如果还是未命中 => 则向 DNS 服务器发送请求获取. 在向 DNS 服务器获取 IP 地址之前的行为, 叫做 DNS 本地解析.
ZLIB
在网络传输过程中, 如果网速稳定的情况下, 对数据进行压缩, 压缩比率越大, 那么传输的效率就越高等同于速度越快了. zlib 模块提供了 Gzip/Gunzip, Deflate/Inflate 和 DeflateRaw/InflateRaw 等压缩方法的类, 这些类接收相同的参数, 都属于可读写的 Stream 实例.
TODO
RPC
RPC (Remote Procedure Call Protocol) 基于 TCP/IP 来实现调用远程服务器的方法, 与 http 同属应用层. 常用于构建集群, 以及微服务 (推荐一本《Node.js 微服务》虽然我还没看完)
常见的 RPC 方式:
- Thrift
- HTTP
- MQ
Thrift
Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。它通过一个代码生成引擎联合了一个软件栈,来创建不同程度的、无缝的跨平台高效服务,可以使用C#、C++(基于POSIX兼容系统)、Cappuccino、Cocoa、Delphi、Erlang、Go、Haskell、Java、Node.js、OCaml、Perl、PHP、Python、Ruby和Smalltalk。虽然它以前是由Facebook开发的,但它现在是Apache软件基金会的开源项目了。该实现被描述在2007年4月的一篇由Facebook发表的技术论文中,该论文现由Apache掌管。
HTTP
gRPC is an open source remote procedure call (RPC) system initially developed at Google. It uses HTTP/2 for transport, Protocol Buffers as the interface description language, and provides features such as authentication, bidirectional streaming and flow control, blocking or nonblocking bindings, and cancellation and timeouts. It generates cross-platform client and server bindings for many languages.
MQ
使用消息队列 (Message Queue) 来进行 RPC 调用 (RPC over mq) 在业内有不少例子, 比较适合业务解耦/广播/限流等场景.
TODO
No Comments