存储
存储
-
[Point]Sql -
[Point]NoSql -
[Point]缓存 -
[Point]数据一致性
简介
科班的同学可以了解一下数据库范式, 在 ElemeFe 面试不会问, 但是其他地方可能会问 (比如阿里).
Mysql
SQL (Structured Query Language) 是关系式数据库管理系统的标准语言, 关于关系型数据库这里主要带大家看一下 Mysql 的几个问题
存储引擎
| attr | MyISAM | InnoDB |
|---|---|---|
| Locking | Table-level | Row-level |
| designed for | need of speed | high volume of data |
| foreign keys | × (DBMS) | ✓ (RDBMS) |
| transaction | × | ✓ |
| fulltext search | ✓ | × |
| scene | lots of select | lots of insert/update |
| count rows | fast | slow |
| auto_increment | fast | slow |
- 你的数据库有外键吗?
- 你需要事务支持吗?
- 你需要全文索引吗?
- 你经常使用什么样的查询模式?
- 你的数据有多大?
索引
索引是用空间换时间的一种优化策略. 推荐阅读: mysql索引类型 以及 主键与唯一索引的区别
Mongodb
Monogdb 连接问题(超时/断开等)有可能是什么问题导致的?
- 网络问题
- 任务跑不完, 超过了 driver 的默认链接超时时间 (如 30s)
- Monogdb 宕机了
- 超过了连接空闲时间 (connection idle time) 被断开
- fd 不够用 (ulimit 设置)
- mongodb 最大连接数不够用 (可能是连接未复用导致)
- etc...
other
populate
aggregate
pipeline
Cursor
整理中
Replication
备份数据库与 M/S, M/M 等部署方式的区别?
关于数据库基于各种模式的特点全部可以通过以下图片分清:
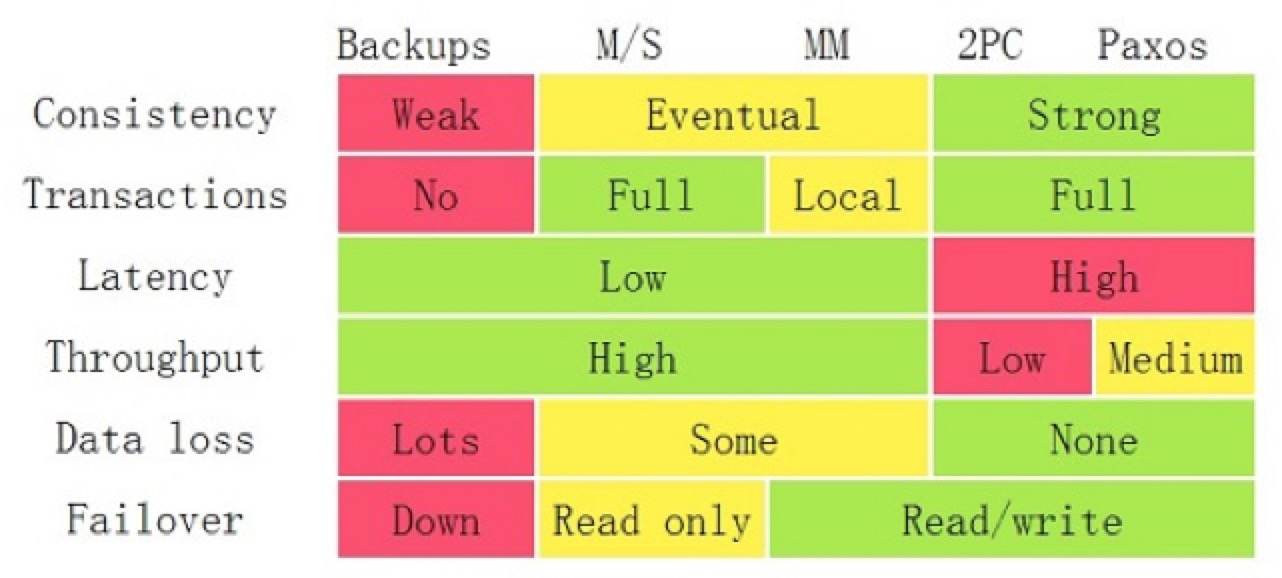
图片出处:Google App Engine 的 co-founder Ryan Barrett 在 2009 年的 google i/o 上的演讲 《Transaction Across DataCenter》(视频: http://www.youtube.com/watch?v=srOgpXECblk)
根据上图, 我们可以知道 Master/Slave 与 Master/Master 的关系.
| attr | Master/Slave | Master/Master |
|---|---|---|
| 一致性 | Eventually:当你写入一个新值后,有可能读不出来,但在某个时间窗口之后保证最终能读出来。比如:DNS,电子邮件、Amazon S3,Google搜索引擎这样的系统。 | |
| 事务 | 完整 | 本地 |
| 延迟 | 低延迟 | |
| 吞吐 | 高吞吐 | |
| 数据丢失 | 部分丢失 | |
| 熔断 | 只读 | 读/写 |
读写分离
读写分离是在 query 量大的情况下减轻单个 DB 节点压力, 优化数据库读/写速度的一种策略. 不论是 MySQL 还是 MongoDB 都可以进行读写分离.
读写分离的配置方式直接搜索一下 数据库名 + 读写分离 即可找到. 通常是 M/S 的情况, 使用 Master 专门写, 用 Slave 节点专门读. 使用读写分离时, 请确认读的请求对一致性要求不高, 因为从写库同步读库是有延迟的.
数据一致性
关于数据一致性推荐看陈皓的分布式系统的事务处理
什么情况下数据会出现脏数据? 如何避免?
- 从 A 帐号中把余额读出来
- 对 A 帐号做减法操作
- 把结果写回 A 帐号中
- 从 B 帐号中把余额读出来
- 对 B 帐号做加法操作
- 把结果写回 B 帐号中
为了数据的一致性, 这6件事, 要么都成功做完, 要么都不成功, 而且这个操作的过程中, 对A、B帐号的其它访问必需锁死, 所谓锁死就是要排除其它的读写操作, 否则就会出现脏数据 ---- 即数据一致性的问题.
这个问题并不仅仅出现在数据库操作中, 普通的并发以及并行操作都可能导致出现脏数据. 避免出现脏数据通常是从架构上避免或者采用事务的思想处理.
矛盾
- 1)要想让数据有高可用性,就得写多份数据
- 2)写多份的问题会导致数据一致性的问题
- 3)数据一致性的问题又会引发性能问题
强一致性必然导致性能短板, 而弱一致性则有很好的性能但是存在数据安全(灾备数据丢失)/一致性(脏读/脏写等)的问题.
目前 Node.js 业内流行的主要是与 Mongodb 配合, 在数据一致性方面属于短板.
事务
事务并不仅仅是 sql 数据库中的一个功能, 也是分布式系统开发中的一个思想, 事务在分布式的问题中可以称为 "两阶段提交" (以下引用陈皓原文)
第一阶段:
- 协调者会问所有的参与者结点,是否可以执行提交操作。
- 各个参与者开始事务执行的准备工作:如:为资源上锁,预留资源,写undo/redo log……
- 参与者响应协调者,如果事务的准备工作成功,则回应“可以提交”,否则回应“拒绝提交”。
第二阶段:
- 如果所有的参与者都回应“可以提交”,那么,协调者向所有的参与者发送“正式提交”的命令。参与者完成正式提交,并释放所有资源,然后回应“完成”,协调者收集各结点的“完成”回应后结束这个Global Transaction。
- 如果有一个参与者回应“拒绝提交”,那么,协调者向所有的参与者发送“回滚操作”,并释放所有资源,然后回应“回滚完成”,协调者收集各结点的“回滚”回应后,取消这个Global Transaction。
异常:
- 如果第一阶段中,参与者没有收到询问请求,或是参与者的回应没有到达协调者。那么,需要协调者做超时处理,一旦超时,可以当作失败,也可以重试。
- 如果第二阶段中,正式提交发出后,如果有的参与者没有收到,或是参与者提交/回滚后的确认信息没有返回,一旦参与者的回应超时,要么重试,要么把那个参与者标记为问题结点剔除整个集群,这样可以保证服务结点都是数据一致性的。
- 第二阶段中,如果参与者收不到协调者的commit/fallback指令,参与者将处于“状态未知”阶段,参与者完全不知道要怎么办。
缓存
redis 与 memcached 的区别?
| attr | memcached | redis |
|---|---|---|
| struct | key/value | key/value + list, set, hash etc. |
| backup | × | ✓ |
| Persistence | × | ✓ |
| transcations | × | ✓ |
| consistency | strong (by cas) | weak |
| thread | multi | single |
| memory | physical | physical & swap |
其他
- zookeeper
- kafka
- storm
- hadoop
- spark
No Comments