异步嵌套解决方案
promise
每一个异步请求立刻返回一个Promise对象,由于是立刻返回,所以可以采用同步操作的流程。而Promise的then方法,允许指定回调函数,在异步任务完成后调用
下面的setTimeout()可以代替理解为一个ajax请求,所以ajax请求同理
function a() {
return new Promise(function (resolve, reject) {
setTimeout(function () {
console.log('执行任务a');
resolve('执行任务a成功');
}, 1000);
});
}
function b(value) {
console.log(value)
return new Promise(function (resolve, reject) {
setTimeout(function () {
console.log('执行任务b');
resolve('执行任务b成功');
}, 2000);
});
}
function c() {
console.log('最后执行c')
}
a().then(b).then(c);
- 如果then里return的值是promise则将resolve的结果传入下一个then
- 如果then里return返回的不是promise则将结果直接传入下一个then
类promise
很多像promise的异步封装方法,比如angular1.x内置封装的$http方法,如下,可以实现多个回调的链式调用,避免了金字塔式的回调地狱
//1
$http({
method: 'GET',
url: 'news.json',
}).then(function successCallback(response) {
console.log(response)
}, function errorCallback(response) {
console.log(response)
})
//2
.then(function() {
return $http({
method: 'GET',
url: 'data.json',
})
}).then(function(data) {
console.log(data)
})
//3
.then(function() {
setTimeout(function() {
console.log("定时器")
}, 1000)
})
await
await 是个运算符,用于组成表达式,await 表达式的运算结果取决于它等的东西。
如果它等到的不是一个 Promise 对象,那 await 表达式的运算结果就是它等到的东西。
如果它等到的是一个 Promise 对象,await 就忙起来了,它会阻塞后面的代码,等着 Promise 对象 resolve,然后得到 resolve 的值,作为 await 表达式的运算结果。
function a() {
return new Promise(function(resolve){
setTimeout(()=>{
console.log("a")
resolve()
},1000)
});
}
function b() {
return new Promise(function(resolve){
setTimeout(()=>{
console.log("b")
resolve()
},1000)
});
}
function c() {
return new Promise(function(resolve){
setTimeout(()=>{
console.log("c")
resolve()
},1000)
});
}
//ES6
a()
.then(b)
.then(c);
//ES2017
await a();
await b();
await c();
await等待的虽然是promise对象,但不必写.then(..),直接可以得到返回值,所以使用await就没有了多个then的链式调用
var sleep = function (time) {
return new Promise(function (resolve, reject) {
setTimeout(function () {
resolve();
}, time);
})
};
var start = async function () {
// 在这里使用起来就像同步代码那样直观
console.log('start');
await sleep(3000);
console.log('end');
};
start();
- async表示这是一个async函数,await只能用在这个函数里面。
- await表示在这里等待promise返回结果了,再继续执行。
- await后面跟着的应该是一个promise对象(当然,其他返回值也没关系,不过那样就没有意义了)
deferred
$.ajax()操作完成后,如果使用的是低于1.5.0版本的jQuery,返回的是XHR对象,你没法进行链式操作;如果高于1.5.0版本,返回的是deferred对象,可以进行链式操作,done()相当于success方法,fail()相当于error方法。采用链式写法以后,代码的可读性大大提高,deferred对象的一大好处,就是它允许你自由添加多个回调函数
$.when(function(dtd) {
var dtd = $.Deferred(); // 新建一个deferred对象
setTimeout(function() {
console.log(0);
dtd.resolve(1); // 改变deferred对象的执行状态 触发done回调
//dtd.reject(); //跟resolve相反,触发fail回调
}, 1000);
return dtd;
}()).done(function(num) {
console.log(num);
}).done(function() {
console.log(2);
}).done(function() {
console.log(2);
})
//ajax默认就是返回deferred对象
$.when($.post("index.php", {
name: "wscat",
}), $.post("other.php"))
.done(function(data1, data2) {
//两个ajax成功才可以进入done回调
console.log(data1, data2);
}).fail(function(err) {
//其中一个ajax失败都会进入fail回调
console.log(err)
})
event loop
先处理微任务队列再处理宏任务队列
| 微任务 | 宏任务 |
|---|---|
| then | setTimeout |
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);//定时器为宏任务
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {//then为微任务
console.log('promise2');
});
console.log('script end');
//先同步后异步
//先清空微任务再清空宏任务
输出的顺序是: script start, script end, promise1, promise2, setTimeout
console.log('script start');
setTimeout(function() {
console.log('timeout1');
}, 10);
new Promise(resolve => {
console.log('promise1');
resolve();
setTimeout(() => console.log('timeout2'), 10);
}).then(function() {
console.log('then1')
})
console.log('script end');
输出的顺序是: script start, promise1, script end, then1, timeout1, timeout2
配置await/async环境
安装一下依赖
npm i -D babel-core babel-polyfill babel-preset-es2015 babel-preset-stage-0 babel-loader
新建 .babelrc 文件,输入以下内容
{
"presets": [
"stage-0",
"es2015"
]
}
新建一份index.js,把你的逻辑文件 app.js,后面require的任何模块都交给babel处理,polyfill支持 await 和 async
require("babel-core/register");
require("babel-polyfill");
require("./app.js");
参考Babel 6 regeneratorRuntime is not defined
await,async,promise三者配合
//async定义里面的异步函数顺序执行
((async() => {
try {
//await相当于等待每个异步函数执行完成,然后继续下一个await函数
const a = await (() => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(1)
resolve(2);
//reject(3)
}, 1000)
});
})();
const b = await (() => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(1)
//resolve(2);
reject(3)
}, 1000)
});
})();
console.log(4)
console.log(a) //3
return b;
} catch(err) {
//上面try中一旦触发reject则进入这个分支
console.log(err);
return err;
}
})()).then((data) => {
console.error(data)
}).catch((err) => {
console.error(err)
})
//分别输出213
注意点:
- async用来申明里面包裹的内容可以进行同步的方式执行,await则是进行执行顺序控制,每次执行一个await,程序都会暂停等待await返回值,然后再执行之后的await。
- await后面调用的函数需要返回一个promise,另外这个函数是一个普通的函数即可,而不是generator。
- await只能用在async函数之中,用在普通函数中会报错。
- await命令后面的 Promise 对象,运行结果可能是 rejected,所以最好把 await 命令放在 try...catch 代码块中。
当然我个人觉得下面写法比较清晰点
//利用try...catch捕捉Promise的reject
async function ajax(data) {
try {
return await new Promise((resolve, reject) => {
setTimeout(() => {
console.log(data)
resolve(data); //成功
}, 2000);
});
} catch(err) {}
}
async function io() {
try {
const response = await new Promise((resolve, reject) => {
setTimeout(() => {
reject("io"); //失败
}, 1000);
});
//resolve执行才会执行下面这句return
return response
} catch(err) {
console.log(err);
}
}
//异步串行
(async() => {
await ajax("ajax1");
await ajax("ajax2");
await io();
})()
(async() => {
let [ajax1, ajax2] = await Promise.all([ajax("ajax1"), ajax("ajax2"),io()]);
return [ajax1,ajax2]
})()
worker
Web Worker 是 HTML5 标准的一部分,这一规范定义了一套 API,允许一段 JavaScript 程序运行在主线程之外的另外一个线程中。将一些任务分配给后者运行。在主线程运行的同时,子线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务,被 Worker 线程负担了,主线程通常负责 UI 交互就会很流畅,不会被阻塞或拖慢。
<input id="btn" type="button" value="通信" />
<script>
let myWorker = new Worker('./worker.js');
let button = document.querySelector('#btn');
// myWorker.onmessage = function (event) { // 接收
// console.log('子线程通知主线程:' + event.data);
// myWorker.terminate(); // 暂停
// }
myWorker.addEventListener('message', function (e) {
console.log('子线程通知主线程:' + event.data);
myWorker.terminate(); // 暂停
});
// 监听 error 事件
myWorker.addEventListener('error', function (e) {
console.log('错误', e);
});
button.onclick = function () {
myWorker.postMessage("主线程通知子线程"); // 启动消息发送线程发送消息
}
</script>
worker.js
addEventListener('message', function (e) {
postMessage('子线程通知主线程: ' + e.data);
}, false);
由于多线程需要在同域情况下进行,所以我们可以借助 blob 把它放到同一个文件下执行
let script = 'console.log("hello world!");'
let workerBlob = new Blob([script], { type: "text/javascript" });
let url = URL.createObjectURL(workerBlob);
let myWorker = new Worker(url);
堆和栈
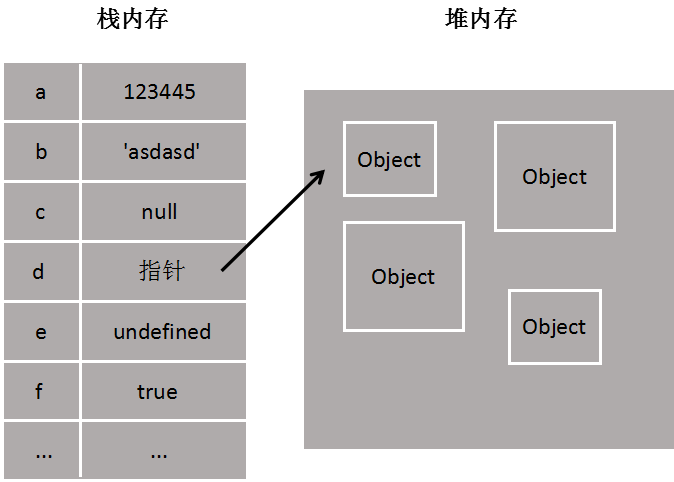
| 区别 | 堆(heap) | 栈(stack) |
|---|---|---|
| 结构 | heap是没有结构的,数据可以任意存放。heap用于复杂数据类型(引用类型)分配空间 | stack是有结构的,每个区块按照一定次序存放(后进先出),stack中主要存放一些基本类型的变量和对象的引用,存在栈中的数据大小与生存期必须是确定的。可以明确知道每个区块的大小,因此,stack的寻址速度要快于heap |
| 速度 | 慢 | 快 |
| 图示 |  |
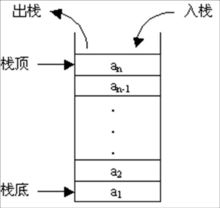 |
| 类型 | 引用类型:对象,数组的内容 | Boolean、Number、String、Undefined、Null,以及对象变量的指针 |
| 堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便 | 栈由系统自动分配,速度较快。但程序员是无法控制的 | |
| 对堆而言,数据项位置没有固定的顺序。你可以以任何顺序插入和删除,因为他们没有顶部数据这一概念 | 对栈而言,栈中的新加数据项放在其他数据的顶部,移除时你也只能移除最顶部的数据(不能越位获取) | |
| 树 | 桶 |
使用new关键字初始化的之后是不存储在栈内存中的。为什么呢?new大家都知道,根据构造函数生成新实例,这个时候生成的是对象,而不是基本类型。再看一个例子
var a = new String('123')
var b = String('123')
var c = '123'
console.log(a==b, a===b, b==c, b===c, a==c, a===c)
>>> true false true true true false
console.log(typeof a)
>>> 'object'
我们可以看到new一个String,出来的是对象,而直接字面量赋值和工厂模式出来的都是字符串。但是根据我们上面的分析大小相对固定可预期的即便是对象也可以存储在栈内存的,比如null,为啥这个不是呢?再继续看
var a = new String('123')
var b = new String('123')
console.log(a==b, a===b)
>>> false false
很明显,如果a,b是存储在栈内存中的话,两者应该是明显相等的,就像null === null是true一样,但结果两者并不相等,说明两者都是存储在堆内存中的,指针指向不一致
说到这里,再去想一想我们常说的值类型和引用类型其实说的就是栈内存变量和堆内存变量,再想想值传递和引用传递、深拷贝和浅拷贝,都是围绕堆栈内存展开的,一个是处理值,一个是处理指针
堆、栈、队列之间的区别是?
- 堆是在程序运行时,而不是在程序编译时,申请某个大小的内存空间。即动态分配内存,对其访问和对一般内存的访问没有区别。
- 栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来。(后进先出)
- 队列只能在队头做删除操作,在队尾做插入操作.而栈只能在栈顶做插入和删除操作。(先进先出)
内存分配和垃圾回收
一般来说栈内存线性有序存储,容量小,系统分配效率高。而堆内存首先要在堆内存新分配存储区域,之后又要把指针存储到栈内存中,效率相对就要低一些了
垃圾回收方面,栈内存变量基本上用完就回收了,而推内存中的变量因为存在很多不确定的引用,只有当所有调用的变量全部销毁之后才能回收
传值和传址
从一个向另一个变量复制引用类型的值,复制的其实是指针,因此两个变量最终指向同一个对象。即复制的是栈中的地址而不是堆中的对象
从一个变量复向另一个变量复制基本类型的值,会创建这个值的副本
No Comments